GTC 2024強強聯手更上層樓
先探投資週刊 2024-03-21 13:41
一年一度的 GTC 大會風光落幕,此次帶來最新AI晶片、超級電腦、人型機器人計畫等重磅消息,大幅度的AI應用進化,也讓輝達的AI霸主地位更加穩固。
【文/周佳蓉】
距離輝達(Nvidia)首屆舉辦GTC大會的二○○九年,已十五個年頭匆匆過去,如今輝達在全世界半導體的地位已不可同日而語,繼二三年衝破一兆美元,今年市值再度衝刺超過二.二兆美元,美股排名僅次於微軟(Microsoft)和蘋果(Apple)兩大科技巨頭之後,暌違五年的實體盛會,全球將GTC大會視作全球AI風向球,創辦人黃仁勳的演講談話也動見觀瞻。三月十八日對著會場座無虛席的人群,黃仁勳幽默地澄清:「這不是一場音樂會」,並表示能召集全球價值高達一○○兆美元、大量非IT行業代表參與此盛會,感到相當自豪。
發表新一代 AI GPU B200
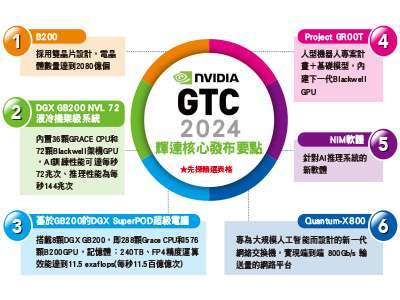
輝達按照每兩年的更新頻率,升級一次GPU架構,從二二年首發採用 Hopper 架構的 H100 起引領著輝達穩坐AI晶片霸主地位,這次再推出採用 Blackwell 架構的 GPU-B200。
B200 是由台積電的五奈米家族(N4P)製程打造而成,並整合兩個獨立製造的裸晶(Die),共含二○八○億個電晶體,B200 透過小晶片(Chiplet)先進封裝將八顆 HBM3e 高頻寬記憶體,記憶體達到一九二GB、頻寬達一.八 TB/s,並預告今年稍晚會推出。
GB200 則是由兩個 Blackwell GPU 和一個既有的 ARM 架構的 Grace CPU 組成的更強大AI加速晶片,延伸的還有基於 GB200 打造的 DGX GB200 NVL72,以及運算效能更強大的超級電腦 DGX SuperPOD。
相比 Hopper 和 Ampere 架構,Blackwell 架構的 B200 性能有了巨幅提升,最大可支援十兆參數的模型訓練,以 OpenAI 的 GPT-3 和 GPT-4 做比較,最高分別支援為一七五○億和一.八兆個參數,而 NVLink 是由輝達開發作為 CPU/GPU 間的高速互聯通道,可最大化提升 CPU/GPU 的傳輸效率,如今已進化到第五代,成為 B200 傳輸速度能大幅提升的關鍵。
全新的加速運算平台 DGX GB200 NVL 72,則擁有九個機架,共搭載十八個 GB200 加速卡,一套 DGX 版內部使用五千條 NVLink 銅纜線,累計長度綿延近二公里,可以減少二○KW的運算能耗,與相同數量的 H100 GPU 相比,在大型語言模型(LLM)推理工作性能可提升三○倍,成本和能耗最多可降低二五倍,針對AI運算需求龐大的企業,輝達目前已宣布亞馬遜AWS計畫採購由二萬片 GB200 晶片組建的伺服器,Dell、 Alphabet、Meta、Mirosoft、OpenAI、Oracle 和特斯拉也將成為 DGX GB200 伺服器的採用者。
晶片仰賴台積電 N4P 製程
而 DGX SuperPOD 為新一代超級電腦平台,由八套 DGX GB200 系統打造而成,採用液冷設計,提供十一.五 exaflops AI 運算能力,輝達強調若企業預算足夠,最終可擴展至數萬個 GB200 超級晶片,並透過 NVLink 連接五七六個 Blackwell GPU,取得龐大共享記憶體。
值得注意的是,輝達也發表了新款基於大規模AI的網路交換機 X800 系列,以及人形機器人的模型 GR00T 專案,該專案內含開發套件 Jetson Thor、更新的 ISAAC Lab 開發工具庫,GB200 可透過 X800 取得八○○Gb/s 超高速網路,而 GR00T 允許開發者利用平台模擬機器人學習技能,支持數千個機器人同步訓練與模擬。
繼硬體之後,軟體服務也是輝達不可或缺的護城河之一,輝達發表了整合AI開發軟體微服務系統的NIM,透過直接提供多產業、多模態的專有模型,讓缺乏AI開發經驗的傳統行業也有機會跨入。
不論是 B100、B200 晶片的推出都仰賴台積電的 N4P 製程,是台積電基於五奈米技術的效能強化版本,儘管此次輝達的晶片並非如外界預期直接導入三奈米製程,不過也是輝達首款採用小晶片(Chiplet)及 CoWoS-L 形式先進封裝的產品,解決高耗電量與散熱問題,而隨著台積電對於先進製程、先進封裝的擴廠動作積極,相關半導體設備、耗材股可望持續大啖商機。(全文未完)
來源:《先探投資週刊》2292 期
更多精彩內容請至 《先探投資週刊》
- 掌握全球財經資訊點我下載APP
延伸閱讀
上一篇
下一篇